This is the final of the three voice explorations in our multivocal AI voice cloning explorations.
This voice design approach builds on a dataset with two different speakers, similar to The Pooled Voice. However, whereas The Pooled Voice splits the different speakers into separate audio files, The Fluctuating Voice instead puts both speakers into the same audio files. For our experiments into this approach, we used two completely different speakers reading different scripts. The audio files do not contain a complete 50/50 split between speaker 1 and speaker 2, but the total amount of audio from both speakers is more or less equal.
The voices in The Fluctuating Voice dataset come from Kimberly Krause’s reading of Eight Girls and a Dog and Piotr Nater’s reading of The Mysterious Island, both found on the public domain audiobook site Librivox.
The voice is trained using Tacotron2 in justinjohn036’s Google Colab notebook.
An example of the dataset behind The Fluctating Voice can be heard here saying “Yes, said brilliant Nan. The wind veers to the northwest”:
The end result of The Fluctuating Voice is a synthetic voice that switches between both speakers in the middle of an utterance. The speaker usually changes between words, but in some cases, the shift occurs inside a word pronunciation. When the switch happens in the middle of a word, the shift can be audibly heard as a type of modulation between the two voices.
You can hear the shifting and bending nature of The Fluctuating Voice in the following two examples, reading two different paragraphs from this article on Vox.com:
The Fluctuating Voice seems to have a lot of aesthetic potential. The way that the voice switches in the middle of an utterance is quite unique to synthetic voices, and is hard to reproduce in traditional audio software. The artist does not really have any control of when and how the voice shifts from one to the other, but this loss of control can again be quite interesting as an artistic tool. Leaving the voice change up to statistical probability opens up opportunities for surprising and serendipitous vocal experiences.
This is the second of the three voice explorations in our multivocal AI voice cloning explorations.
This voice is created by providing a dataset, which consists of audio files from two different speakers. The two speakers are actually the same, but one of them is pitched down. The voice data comes from Kimberly Krause’s reading of Eight Girls and a Dog, found on the public domain audiobook site Librivox. We call this The Pooled Voice to reflect the fact that the voices have been mixed into the same pool.
The voice is trained using Tacotron2 in justinjohn036’s Google Colab notebook.
You can hear an example of the first voice in the dataset here saying “Margy, she said despairingly, I hope you packed the medicine chest I gave you”:
An example of the second voice in the dataset can be heard here saying “Chapter one of Eight Girls and a Dog”:
With this approach, we have decided to go in a different direction than what is generally recommended for voice cloning, which is to have one speaker per dataset. By mixing multiple voices into the dataset instead, we encourage the software to consider both of the voices as part of the same synthetic voice.
However, the resulting synthetic voice does not manifest as a combination of both speakers. Instead, when synthesizing new utterances, the model tends to choose one of the two voices to speak with. It seems as if the model first decides which voice is most likely to be speaking the initial segment of the generated audio, and this decision sets the precedent for the rest of the audio. This makes sense considering that a model like this is more or less an “autocorrect for sound”. It starts by creating the first piece of audio, and then piece-by-piece adds more and more to match the provided sentence.
In this synthetic utterance by The Pooled Voice, we can hear that the pitched down voice is used for the sentence “Choose the voice you’d like to use”:
When instructed to say the words “Hello world”, The Pooled Voice produces the original non-pitched voice from the dataset:
Running the model with the same sentence multiple times always gave the same results, where one voice would be produced instead of another.
Artistically, The Pooled Voice has limited potential. In the end, it seems to act as a sort of random picker of voices. The artist has no direct control over which voice gets produced, and as such a certain level of control is given up to the machine learning model. Yet since machine learning is based on statistical inference, this loss of control cannot simply be replaced by an auxiliary random function.
This is the first of the three voice explorations in our multivocal AI voice cloning explorations.
This voice is created by layering three editions of the same voice on top of each other. The original voice comes from Kimberly Krause’s reading of Eight Girls and a Dog, found on the public domain audiobook site Librivox. One of the voices in our dataset is pitched down, another is pitched up and the third voice is the default pitch. This somewhat emulates the idea of a choir, which is why we named this approach The Choral Voice.
The voice is trained using Tacotron2 in justinjohn036’s Google Colab notebook.
You can hear an example from the choral dataset reading the text “Have your pitchers bigger than your pillows and the thing is done” below:
After a couple of hours of training, the result of the voice clone is a synthetic voice that sounds quite a lot like the original data. One of the main downsides by this approach, however, is that the intelligibility of both the original voice data and the resulting synthetic voice is very low. It is hard to tell what is being said with this type of multivocal voice. However, we were positively surprised that the voice cloning software was able to faithfully reproduce audio with multiple voices inside it.
You can hear an example of The Choral Voice saying “Choose the voice you’d like to use” below:
From an aesthetic point of view, The Choral Voice approach shows that the machine learning model is quite capable of picking up the connection between text and audio, even when the training data has low intelligibility. This opens up the opportunity for manipulating the original dataset even more to create novel ways of synthesizing voices. As long as it is possible to establish a statistical connection between utterance and text, Tacotron2 seems capable of reproducing the original in the synthesized version.
An audio effect that turns a single voice into a multitude of individual voices, each with their own unique timbre and character.
The choir of voices is recreated by manipulating original audio in real-time.
Each voices has its own variation on timing, pitch and formant-shifting.
The number of voices is limited only by the available processing power.

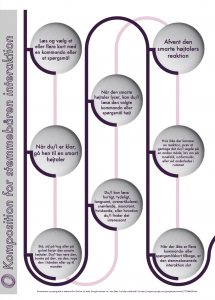
This is the score. Graphical work and layout by Emilie Oksholt


These are examples of the cards for performative vocal interaction. There are eight performative vocal interaction cards in total. Graphical work and layout by Emilie Oksholt.

To be read aloud by two speakers; speaker one, speaker two, both speakers. The sounds in the room where the composition takes place, can replace the sounds referred to in the score (e.g. projector, shoes).